Shh…The Secret to Building Great AI
Oct 15, 2019 00:11 · 832 words · 4 minute read

I apologize for the somewhat clickbait title, but I just had to create the meme above after seeing Elon Musk’s tweet:
I thought that was hilarious…anyways, back to your regular programming.
When you finish a PhD in machine learning, they take you to a special room and explain that great data is way more important than all the fancy math and algorithms you just learned
At least, that is how I imagine it. I don’t have a Ph.D., so I couldn’t say for sure, but it seems likely.
Data » Algorithms
That is it — the secret to building great AI systems — have great data. I could end the article here, but let’s take a look at some supporting facts:
First, accuracy improvements from growing data set size and scaling computation are empirically predictable. This was part of the conclusion of the paper Deep Learning Scaling is Predictable, Empirically from a group at Baidu. And here is one of the graphs from their results:
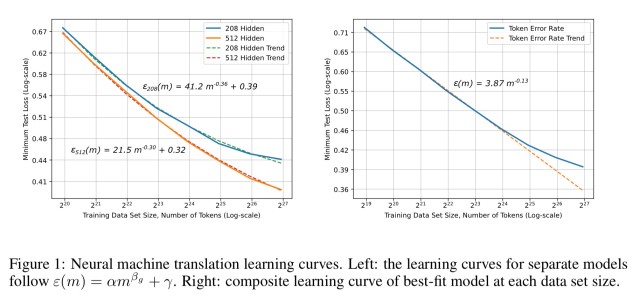
The above graphs are empirically showing that “deep learning model accuracy improves as a power-law as we grow training sets for state-of-the-art (SOTA) model architectures.” Basically, you could use the power law to predict how much better your model would perform given an increase in training data. Now, stop and think about that for a minute. An almost guaranteed way to improve your deep learning model is to gather more data. It is very hard to say the same for the endless weeks of model tweaking and attempts at inventing new architectures. Google saw this as well in their 2009 paper The Unreasonable Effectiveness of Data.
Second, GitHub is full of open-source state-of-the-art algorithms, but open data are much rarer. Want the code to run that latest state of the art deep learning model? You can probably find some version of it on GitHub. Want some data on Google’s search result performance or Netflix viewership? Goodluck. Companies are aware that data advantages are almost always superior to algorithmic advantages. For example, Deep Mind was acquired by Google for an estimated $500+ million. This was a purchase of amazing talent and algorithms. Two years earlier Facebook acquired Instagram for $1 billion. Why is a photo-sharing app worth up to twice as much as Deep Mind? In my opinion, one of the largest reasons is data. As quoted in this Forbes article
Facebook’s databases need this info to optimize the media it will bring to you. This data is WORTH S***LOADS! Imagine you’re a ski resort and want to reach skiiers, Instagram will give them a new way to do that, all while being far more targeted than Facebook otherwise could be.
If you were to sit down and create a list of “great” AI companies, you would almost surely discover that all of them are also great data companies. Building almost magical AI is a lot easier if you can start with vast amounts of data.
Lastly, Google wrote a follow-up paper in 2017 to their work on the Unreasonable Effectiveness of Data titled Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. Here is a chart from the paper:
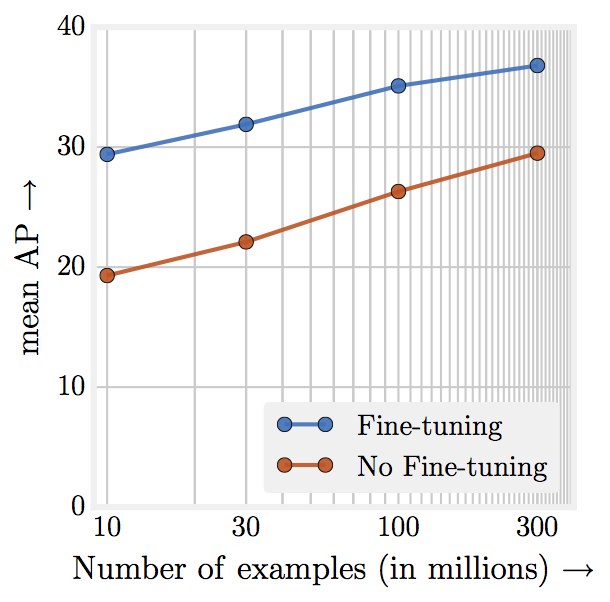 Source: Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
Source: Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
Which, among other things, shows that performance increases logarithmically based on the volume of training data. There is also an amazing quote at the conclusion of the paper:
While a tremendous amount of time is spent on engineering and parameter sweeps; little to no time has been spent collectively on data. Our paper is an attempt to put the focus back on the data.
Put the Focus Back on the Data
How many companies today are talking about building a data science team? I get it — it is sexy to hire that incredibly smart Ph.D. student from MIT. And I am not saying that is a bad thing. But. How many of these same companies are talking about investing in building larger and better datasets? Too often, I see companies treating data as a fixed asset or they are extremely skeptical in data investments. Go ahead, ask for $100k to create your own, proprietary dataset which would increase your scale of data 10–1,000x. Let me know how that conversation goes (that same executive, though, would probably be a lot more excited about hiring another data scientist).
I hope I have convinced you to think more strategically about data and its value in your AI efforts. I challenge you to sit down today and think about how you can get more and better data for whatever problem you are trying to solve. It might be something as simple as turning on Google Analytics for your start-up eCommerce shop. The data science unicorn you hire in the future will thank you.
I read a lot about data science and leadership. I thought it might be helpful for others to send a weekly email with my top 3 favorite articles of the week. If you are interested, sign up below!