One Word of Code to Stop Using Pandas So Slowly
Nov 2, 2019 16:05 · 525 words · 3 minute read
 Photo by Lance Anderson on Unsplash
Photo by Lance Anderson on Unsplash
You have your data all loaded into a Panda’s dataframe, ready to do some exploratory analysis, but first, you need to create a few additional features. Naturally, you turn to the apply function. Apply is great because it makes it easy to use a function on all the rows of your data. You get it all set up, run your code and…
Wait
It turns out it can take a while to process every row of a large dataset. Thankfully, there is a very simple solution that could save you a significant amount of time.
Swifter
Swifter is a library which, “applies any function to a pandas dataframe or series in the fastest available manner.” To understand how we need to first discuss a few principles.
Vectorization
For this use case, we will define vectorization as using Numpy to express calculations on entire arrays instead of their elements.
For example, imagine you have two arrays:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])
And you wish to create a new array which is the sum of the two arrays resulting in this:
result = [7,9,11,13,15]
You could sum these arrays with a for-loop in Python, but that is very slow. Instead, Numpy allows you to operate directly on the arrays, which is significantly faster (especially with large arrays)
result = array_1 + array_2
The key takeaway is that you want to use vectorized operations whenever possible.
Parallel Processing
Pretty much all computers have multiple processors. That means that you can speed up your code pretty easily for some things by utilizing them all. Since apply is just applying a function to every row of our dataframe, it is simple to parallelize. You can just split the dataframe into multiple chunks, feed each chunk to its processor, and then combine the chunks back into a single dataframe at the end.
The Magic
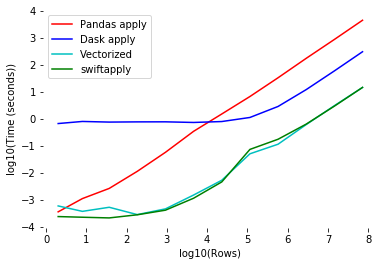 Source: https://github.com/jmcarpenter2/swifter
Source: https://github.com/jmcarpenter2/swifter
What Swifter does is
- Check if your function can be vectorized and if so, just use vectorized computations.
- If vectorization is not possible, check whether it makes the most sense to do parallel processing using Dask or just use vanilla Pandas apply (only uses a single core). The overhead of parallel processing can make the process slower for small datasets.
This is all nicely shown in the graph above. You can see that no matter the data size, you are almost always better off using vectorization. If that is not possible, you get the best speed from vanilla Pandas until your data are of a large enough size. Once the size threshold is exceeded, parallel processing makes the most sense.
You can see the “swiftapply” line is what swifter would do and it automatically chooses the best option for you.
How do you make use of this magic you ask? Easy.
Just add the swifter call before the apply as shown above and you are now running your Pandas apply faster than ever with just a single word.
Now, you can spend less time staring at a progress bar and more time doing science. That is life-changing. Though, you may have less time for sword battles.
 Source: https://xkcd.com/303/
Source: https://xkcd.com/303/