Machine learning: introduction, monumental failure, and hope
Oct 20, 2019 03:21 · 1622 words · 8 minute read
 Photo by Ahmed Hasan on Unsplash
Photo by Ahmed Hasan on Unsplash
What is Machine Learning?
Wikipedia tells us that Machine learning is, “a field of computer science that gives computers the ability to learn without being explicitly programmed.” It goes on to say, “machine learning explores the study and construction of algorithms that can learn from and make predictions on data — such algorithms overcome following strictly static program instructions by making data-driven predictions or decisions, through building a model from sample inputs.”
Learning from inputs
What does it mean to learn from inputs without being explicitly programmed? Let us consider a classical machine learning problem: spam filtering.
Imagine that we know nothing about machine learning, but are tasked with determining whether an email consists of spam or not. How might we do this? Here are some of my ideas:
- Analyze the IP address. From the IP address, we can usually determine the location of the sender and spam might more often come from locations that are not close to the receiver.
- Look at the text of the email. Any references to a Nigerian Prince?
- Look for uncommon email address patterns. For example, are there a significant amount of numbers at the end of the email address?
Those are just a few ideas, but hopefully, you have thought of some more as well.
Now imagine we have a black-box that if given a great many examples of emails that are spam and not spam, could take these examples and learn from the data what spam looks like. We will call this black-box machine learning. And often the data we feed it are called features.
Want a more visual example of learning from inputs? Take a look at this program using machine learning to learn how to play Flappy Bird.
Why machine learning?
After going through the spam example above, you might wonder: why do we need machine learning to detect spam? It seems like humans or a rule-based program could handle that task very well. Here are some of the benefits:
- Scale. It is significantly easier to scale a machine learning algorithm than a human. A single machine could analyze thousands (if not more) of emails a minute for spam.
- Cost. While there is a larger upfront cost to developing machine learning, the lifetime cost can be significantly lower if you are successful in developing an effective algorithm.
- Robust. One of the beauties of machine learning is it is can be much easier to adapt to new trends. If you have developed thousands of lines of rules to detect spam and then a new type of spam is released (perhaps an email saying you’ve won the lottery), it can be hard to update your rules without breaking previous rules. With a machine learning algorithm, all you would need are data on the new trend and then just re-train your algorithm — it will take care of adjusting to the trend.
- Smart. Humans and rule-based programs can often struggle with developing methods to detect challenging cases. For example, writing rules for all the text-based patterns that could exist in spam is hard. With the rise of more complex models (like deep learning), often the model can do a better job of capturing patterns.
Types of machine learning problems
Now that we have a basis for what machine learning is and why it can be valuable, let’s take a look at some of the types of problems machine learning can solve.
Supervised machine learning problems are ones for which you have labeled data. Labeled data means you give the algorithm the solution with the data and these solutions are called labels. For example, with spam classification, the labels would be “spam” or “not-spam.” Linear regression would be considered an algorithm to solve a supervised problem.
Unsupervised machine learning is the opposite. It is not given any labels. These algorithms are often not as powerful as they don’t get the benefit of labels, but they can be extremely valuable when getting labeled data is expensive or impossible. An example would be clustering.
Regression problems are a class of problems for which you are trying to predict a real number. For example, linear regression outputs a real number and could be used to predict housing prices.
Classification problems are problems for which you are predicting a class label. For example, spam prediction is a classification problem because you want to know whether your input falls into one of two classes: “spam” or “not-spam”. Logistic regression is an algorithm used for classification.
Ranking problems are very popular in eCommerce. These models try to rank the items by how valuable they are to a user. For example, Netflix’s movie recommendations. An example model is collaborative filtering.
Reinforcement Learning is when you have an agent in an environment that gets to perform actions and receive rewards for actions. The model here learns the best actions to take to maximize rewards. The flappy bird video is an example of reinforcement learning. An example model is deep Q-networks.
 Photo by Nathan Dumlao on Unsplash
Photo by Nathan Dumlao on Unsplash
Fails to Deliver
Perhaps my favorite part from the Wikipedia page on machine learning is, “As of 2016, machine learning is a buzzword, and according to the Gartner hype cycle of 2016, at its peak of inflated expectations. Effective machine learning is difficult because finding patterns is hard and often not enough training data is available; as a result, machine-learning programs often fail to deliver.”
Here are some of my thoughts on why machine learning problems can fail to deliver value.
There isn’t a clear problem to solve.
An executive at the company heard machine learning is the next big thing, so they hired a data science team. Unfortunately, there isn’t a clear idea of what problems to solve, so the team flounders for a year.
Labeled data can be extremely important to building machine learning models, but can also be extremely costly.
First off, you often need a lot of data. Google found for representation learning, performance increases logarithmically based on the volume of training data:
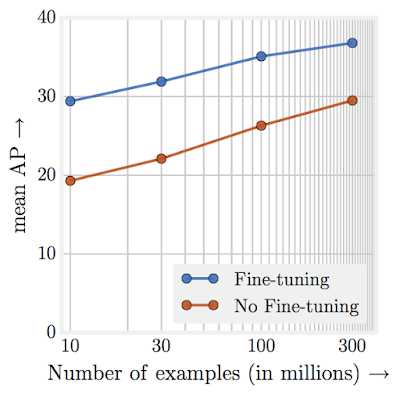
Secondly, you need to get data that represents the full distribution of the problem you are trying to solve. For example, for our spam classification problem, what kinds of emails might we want to gather? What if we only had emails that came from US IP addresses?
Lastly, just getting data labeled can be time-consuming and cost a lot of money. If you don’t already have data for spam classification, who is going to label (and pay for) millions of emails as spam or not spam?
Data can be very messy
Often data in the real world has errors, outliers, missing data, and noise. How you handle these can greatly influence the outcome of your model and takes time and experience to do well.
Feature engineering
Once you have your data and labels, deciding on how to represent it to your model can be very challenging. For example, for spam classification would you just feed it the raw text? What about the origin of the IP address? What about a timestamp? The features you create out of your data usually are even more important than the algorithm you choose.
Your model might not generalize
After all of this, you might still end up with a model that either is too simple to be effective (underfitting) or too complex to generalize well (overfitting). You have to develop a model that is just right. :)
Evaluation is non-trivial
Let’s say we develop a machine learning model for spam classification. How do we evaluate it? Do we care more about precision or recall? How do we tie our scientific metrics to business metrics? Most new data scientists are used to working on problems for which the evaluation metric is already determined. In industry, it can be very challenging to determine what you want to optimize and designing an algorithm to appropriately maximize (or minimize) that metric.
Getting into production can be hard
You have a beautiful model built-in Python only to discover you have no idea how to get it into production. The back-end is in Java and the model has to run in under 5ms. You have no experience with Java and are not sure how to speed up your model. Often companies try and solve this problem by having engineers convert scientist code to production, but that hand-off method can lead to substantial delays and even bugs due to information loss during the process.
 Photo by bruce mars on Unsplash
Photo by bruce mars on Unsplash
Hope
While many machine learning initiatives do fail, many also succeed and are running some of the most valuable companies in the world. Companies like Google, Facebook, Amazon, Airbnb, and Netflix have all found successful ways to leverage machine learning and are reaping large rewards.
Google CEO Sundar Pichai even recently said there is “an important shift from mobile-first world to an AI-first world.”
And Mark Cuban said, “Artificial Intelligence, deep learning, machine learning — whatever you’re doing if you don’t understand it — learn it. Because otherwise you’re going to be a dinosaur within 3 years.”
And lastly, Harvard Business Review found
Companies in the top third of their industry in the use of data-driven decision making were, on average, 5% more productive and 6% more profitable than their competitors
I hope this article has given you a good introduction to the world of machine learning, some of the challenges, and why it can be so valuable. It is now up to you to execute on machine learning at your company and unleash the potential value. If you are looking for some ideas on how to get started, check out another one of my articles:
Delivering on the Promise of Artificial Intelligence
_For Your Startup_towardsdatascience.com