How To Add Confidence Intervals to Any Model
Nov 12, 2019 14:34 · 676 words · 4 minute read
 Photo by Toa Heftiba on Unsplash
Photo by Toa Heftiba on Unsplash
“Can I trust your model?”
It is the first thing your manager asks as you present your latest work. How do you answer? Do you refer to the mean squared error? the R² coefficient? How about some example results? These are all great, but I would like to add another technique to your toolkit —** confidence intervals**.
Trust
At the end of the day, one of the most important jobs any data scientist has is to help people trust an algorithm that they most likely don’t completely understand.
One way to help build this trust is to add confidence intervals to your model’s predictions. We will define confidence intervals for this article as a way of quantifying the uncertainty of an estimate. This tends to be easier for classification problems. Most algorithms provide probability estimates which can serve as confidence scores. For example, a 90% probability of being a cat should be more confident than a 50% probability.
For regression problems, though, things tend to get trickier. Most algorithms don’t have a natural way of providing a confidence or probability score. There are many solutions to this problem, one of my favorite being Bayesian models, but I would like to discuss the simplest and easiest method to implement for any machine learning model.
Bootstrap Resampling
To start, we first need to define a bootstrap sample. Fortunately, this is easy — it is a sample of our dataset, with replacement, where the sample size is the same as the dataset size. This means that the average bootstrap sample contains 63.2% of the original observations and omits 36.8%. The omitted 36.8% of the data are duplicated from the 63.2% of the data contained in the sample. You can read more about how these numbers were calculated here.
This is useful because it is a very simple method by which you can now simulate different underlying datasets while not actually changing the data.
Here is how you would create 1,000 bootstrap samples of a dataset (assuming your X values are in scaled_df and your labels are in target)
Once you have 1,000 samples of your data, you can now train your model 1,000 times and obtain different results. The key is that a result is more robust when slight changes to the input data only lead to slight changes in the output. Let’s take a look at our training (using a simple SGD regressor for this example)
In this example, the result I care about are my model coefficients. You can see in my training loop, that I append them to a list so I can analyze the distribution of the coefficients as seen here:
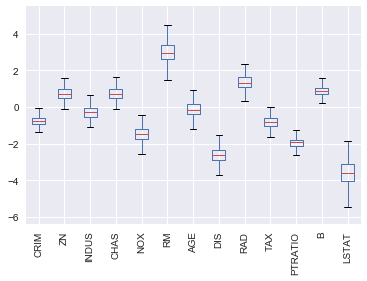
What we have are all my features on the x-axis and the distributions (from the 1,000 models) of the coefficients for these features. This can be extremely helpful when trying to understand how much you can trust these coefficient values.
For example, there are a few variables, such as AGE which span 0. That is not good because not only are you not confident in the point estimate, but you are also not confident in the direction (positive or negative). Other variables, like PTRATIO have a small variance and sit completely on the positive or negative side. These variables give us more confidence.
You can also define probabilistic ranges. If we look closer at LSTAT we would see the following:
mean -3.599465
std 0.687444
min -5.825069
25% -4.058086
50% -3.592409
75% -3.120958
max -1.575822
100 percent of the time the coefficient value fell between -1.57 and -5.82 and the inner quartile range lies between -3.12 and -4.05.
Move Forward with Confidence
Hopefully, this was a useful example of how to increase and measure your confidence in any model. While simple, we have demonstrated that bootstrap resampling can be very illuminating and help build trust in your model. This is hardly the only method to provide confidence intervals and I encourage you to use this as a starting point on your quest to build confidence intervals into your models.