Everything You Ever Wanted to Know About K-Nearest Neighbors
Dec 5, 2019 13:59 · 883 words · 5 minute read
 Photo by Nina Strehl on Unsplash
Photo by Nina Strehl on Unsplash
K-Nearest Neighbors is one of the simplest and easiest to understand machine learning algorithms. It can be used for both classification and regression tasks but is more common in classification, so we will start with that use case. The principles, though, can be used in both cases.
Here is the algorithm:
- Define k
- Define a distance metric — usually Euclidean distance
- For a new data point, find the k nearest training points and combine their classes in some way — usually voting — to get a predicted class
That’s it!
Some of the benefits:
- It doesn’t require any training in the traditional sense. You just need a fast way to find the nearest neighbors.
- Easy to understand and explain.
Some of the negatives:
- You need to define k, which is a hyper-parameter, so it can be tuned with cross-validation. A higher value for k increases bias and a lower value increases variance.
- You have to choose a distance metric and could get very different results depending on the metric. Again, you can use cross-validation to decide on which distance to use.
- It doesn’t really offer insights into which features might be important.
- It can suffer from high dimensional data due to the curse of dimensionality. Basically, the curse of dimensionality means that in high dimensions, it is likely that close points are not much closer than the average distance, which means being close doesn’t mean much. In high dimensions, the data becomes very spread out, which creates this phenomenon. There are so many good resources for this online, that I won’t go any deeper.
Basic assumption:
- Data points that are close share similar values for our target class or value.
Voting Methods
- Majority Voting: After you take the _k n_earest neighbors, you take a “vote” of those neighbors’ classes. The new data point is classified with whatever the majority class of the neighbors is. If you are doing binary classification, it is recommended that you use an odd number of neighbors to avoid tied votes. However, in a multi-class problem, it is harder to avoid ties. A common solution to this is to decrease k until the tie is broken. The fraction of votes for the most common class can also act as a probability score for that class.
- Distance Weighting: Instead of directly taking votes of the k-nearest neighbors, you weight each vote by the distance of that instance from the new data point. A common weighting method is one over the distance between the new data point and the training point. The new data point is added to the class with the largest total weight. Not only does this decrease the chances of ties, but it also reduces the effect of a skewed representation of data.
Distance Metrics
Euclidean distance, or the 2-norm, is a very common distance metric to use for _k-_nearest neighbors. Any p-norm can be used, however. The p-norm is defined as
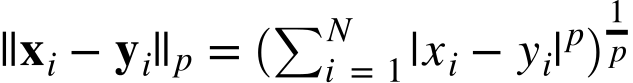
Thus, for any value of p you can define a distance between two points: x and y.
Search Algorithm
As mentioned above, there is no real training other than preparing a way to quickly lookup the neighboring points. Imagine your data set contains 2,000 points. A brute-force search for the 3 nearest neighbors to one point does not take very long. But if the data set contains 2,000,000 points, a brute-force search can become quite costly, especially if the dimension of the data is large. Other search algorithms sacrifice an exhaustive search for faster run time. Structures such as KDTrees or Ball trees are used for faster run times. While we won’t dive into the details of these structures, being aware of them and how they can optimize your run time (although, training time does increase) is important.
Radius Neighbors Classifier
A very related algorithm is the radius neighbors classifier. This is the same idea as a nearest neighbors classifier, but instead of finding the _k-_nearest neighbors, you find all the neighbors within a given radius. Setting the radius requires some domain knowledge; if your points are closely packed together, you’d want to use a smaller radius to avoid having nearly every point vote.
K-Neighbors Regressor
To change our problem from classification to regression, all we have to do is find the weighted average value of the k-nearest neighbors. Instead of taking the majority class, we calculate a weighted average of these nearest values, using the same weighting methods as above. In this case, a “majority vote” would just be a simple average of the neighbors and “distance weighting” would be an average weighted by the distance.
Code!
Let’s take a look at how this all comes together with some Python code:
Source: https://gist.github.com/tfolkman/1f122eb101011edc4a1456c70aef07fd
Once run, you will get:
Best Params: {‘n_neighbors’: 5, ‘p’: 1, ‘weights’: ‘uniform’}
Train F1: 0.9606837606837607
Test Classification Report:
precision recall f1-score support
0 0.97 0.88 0.93 43
1 0.93 0.99 0.96 71
avg / total 0.95 0.95 0.95 114
Train Accuracy: 0.9494505494505494
Test accuracy: 0.9473684210526315
Not bad! Hopefully, this article helped you better understand how K-Nearest Neighbors works and how you can implement it in Python. If you want to learn more machine learning algorithms, definitely check out the book Hands-On Machine Learning with Scikit-Learn and TensorFlow.
Join my email list to stay in touch.