Answers to the 3 Most Common Data Science Questions
Nov 23, 2019 04:06 · 1602 words · 8 minute read
Ask Us Anything
 Photo by Bryan Minear on Unsplash
Photo by Bryan Minear on Unsplash
Earlier this year, I was super excited to join Towards Data Science as an editor. It has been a lot of fun helping the community grow and in this article, I will be contributing to our “Ask Us Anything” series by answer 3 common data science questions. I hope you enjoy!
Should I go to Graduate School?
This is probably the question I receive the most and is probably the hardest to answer. It is difficult to give a generic answer to this question as the answer really needs to be specific to your situation. That being said, I think there are some things that can help make your decision easier. But please remember this is one point of view, mine, and getting more than one data point is usually helpful (this advice applies to all of my answers).
You don’t have to go right after your undergraduate program. Most people seem to think there is a ticking time-bomb during their senior year and if they don’t go to graduate school immediately than surely the opportunity will pass them by. In my experience, this is definitely not the case. If you are unsure about graduate school, please consider whether it makes more sense to wait, get a few years of experience, and then decide.
Most data scientists are not research scientists. If you are considering a Ph.D. as a fast-track to a high paying data science job, then I would reconsider. A Ph.D. program will take at least 4–5 years and it is not uncommon to take 6+ years. That is a long time. And most of the deep research you do will not directly apply to an industry job. That doesn’t mean it isn’t valuable, but there is definitely a non-trivial transition unless you end up in an industry lab doing research. That’s why companies like Insight Data Science exist to help bridge that gap. While you will enter at a higher level than someone without a Ph.D., in my experience, it doesn’t account for the loss of roughly 5 years of significantly higher pay. The monetary sweet spot at the moment seems to be a master’s degree. You take 2 years to get your masters and then 2–3 years of experience and often you are now where a fresh PhD would start, but you were making money for the last 2–3 years. Some argue that a PhD has a higher ceiling and that may be true, but generally, data scientists who truly do well tend to do so because they can bridge the gap between science and company value. I think that skill is fairly evenly distributed across academic backgrounds. Note: a Ph.D. obviously makes a lot more sense if your goal is to be a research scientist.
Which school you go to or lab you join can be more important than what you learn. This is because the current recruiting system is pretty bad and because so many great data science resources can be found openly online. I would argue that everything you need to know to pass a data science interview can be found, for free, online. There are even countless articles on the “best” resources. Then why go to graduate school, you ask? Because while you may know everything you need to know, you need to first get in the door to demonstrate your abilities. And a large way by which companies filter resumes is by the school you attend and whether you have an advanced degree. Did you just graduate from Stanford? You will have an immensely easier time getting interviews than someone who graduated from a lesser-known university. Also, it turns out that well know programs are also excellent opportunities for networking. If you attend a school like Stanford you will almost surely know people at many of the top tech companies as well as growing “unicorn” companies. That network will get you in the door. If you are considering a Ph.D., this same reasoning applies to the Ph.D. lab. You want to closely consider which lab you join because you are tying your value, in some part, to the reputation and value of your lab and advisor.
Do your research. Going to graduate school is a large investment of your time. And your time is extremely valuable. Take time to connect with people on LinkedIn who attended the program you are considering. Connect with professors you think you might want to work with. Call the school’s office and ask them questions. Your goal should be to discover whether your vision of how graduate school will help you aligns with reality. For example, maybe you are considering a master’s program because you think it will help you transition to a job at a company like Google. Then you should do your research and figure out where people end up after the program. If almost everyone ends up in consulting than it is probably not the program for you.
Predicting the future is hard. Hopefully, the above points help your decision, but at the end of the day, there will always be an unknown factor on what the “right” choice is. The best you can do is try and determine what your goals are for the future and then evaluate how graduate school helps you get there vs. other avenues. Then take action and don’t be afraid to re-evaluate and adjust as you learn.
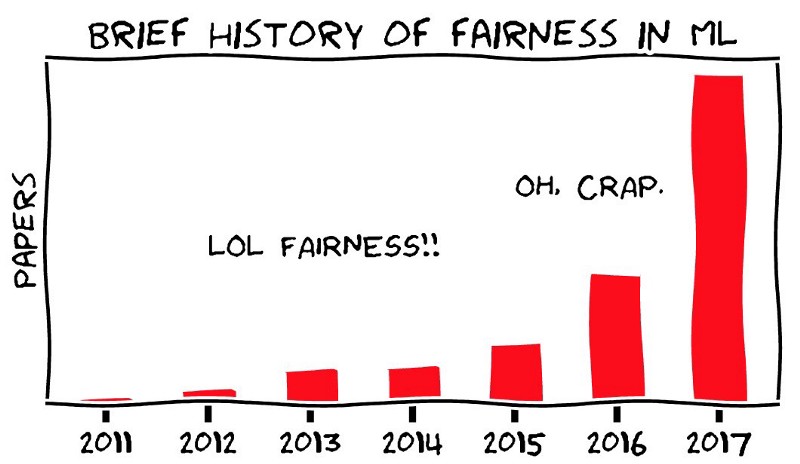 https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb
https://towardsdatascience.com/a-tutorial-on-fairness-in-machine-learning-3ff8ba1040cb
What are the most pressing problems in data science?
I think there are almost too many to count, but here are three that I currently think about a lot.
Fairness and bias. We have built some amazing algorithms, but until somewhat recently have not thought much about how they might be biased or unfair. One of the challenges of this area is that the strength of machine learning is its ability to learn from historical data and apply those patterns to future cases. What do you do though if your historical data are biased? For example, in entertainment, there is historical gender bias. Of the top 250 films of 2017, 88 percent had no female directors, 83 percent had no female writers, and 96 percent had no female cinematographers. So if you were to build a model to predict “good” directors using historical data your model would almost surely be biased. How you mitigate these biases I think will be instrumental in building AI that has a stronger and better impact on society.
Safety. I am super excited about self-driving cars. I love the technology and the application of deep learning at scale. They also deeply worry me in their current state. We have very little in the way of guaranteed safety or performance of these vehicles. This was made very clear with the investigation into Uber’s fatal crash.
“Although the [Automatic Driving System] sensed the pedestrian nearly six seconds before the impact, the system never classified her as a pedestrian — or predicted correctly her goal as a jaywalking [sic] pedestrian or a cyclist — because she was crossing … at a location without a crosswalk,” the report said. “The system design did not include a consideration for jaywalking pedestrians.”
Basically, Uber forgot to account for jaywalking pedestrians. I can imagine so many similar edge cases such as these that I can’t help but wonder how we might quantify or even formally verify the safety of AI-based systems.
Small Data and Compute. Big data and deep learning algorithms are super sexy. It also turns out they can be very bad for the environment as well as not applicable to many important problems. I’m excited by the research being done on making our algorithms much more compute and data-efficient. For example, Google’s MorphNet has a nice shirking algorithm that allows you to extract a more efficient network from a large network. I think this will make cutting edge algorithms more available to entities without large compute budgets as well as applicable to small data problems such as predicting rare diseases.
Should I Learn Python or R or something else?
I actually have a pretty strong opinion on this subject. Before I give it, though, I think at the end of the day what matters most is learning data science. The programming language you use to implement it doesn’t really matter if you have a strong base of knowledge. Also, programming languages come and go so the ability to transition is definitely valuable.
That being said, in today’s environment and for the problems I mostly work on (applied AI in industry), I think you’d be crazy not to start with Python. Python is a general-purpose programming language that has strong machine learning support. R is a language built specifically for statistical computing and graphics which I think limits it in today’s environment.
Python is significantly easier to ship to production, better prepares you to learn different programming languages that might develop, has better deep learning support, and is easier to scale. Also, the support for Python in the open-source machine learning community is huge. Almost every popular package being released is in Python. I know R also has a great community and support as well, but its strength lies more in niche statistical needs (which may not be so niche depending on the area in which you work) and exploratory data analysis. But I think for most of your exploratory data needs Python has pretty much caught up.
So — for me, Python is a no brainer, but I am a sample size of 1. Why not try both? And decide for yourself.